記事本文抽出ツール:Webページの記事本文を一括抽出・保存!
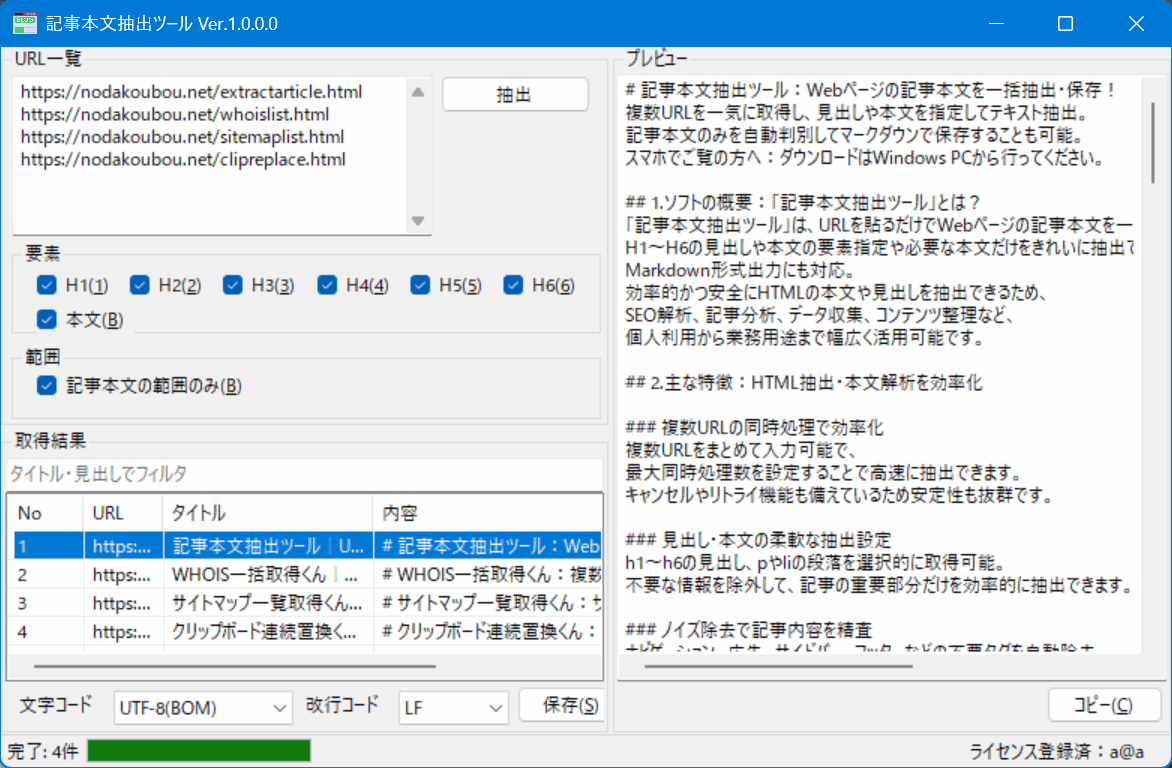
複数URLを一気に取得し、記事本文のみテキストデータとして取得可能。
出力対象(見出し1~6、本文)を指定できるため、見出し構造のみ出力も可能。
スマホでご覧の方へ:ダウンロードはWindows PCから行ってください。
1.ソフトの概要:「記事本文抽出ツール」とは?
「記事本文抽出ツール」は、URLを貼るだけでWebページの記事本文を一括抽出できるWindows向けソフトです。
要素指定(H1~H6の見出し、本文)を指定し、必要な本文だけをきれいに抽出できます。
見出しはMarkdown形式で出力されるため、すぐ活用できます。
効率的かつ安全にHTMLの本文や見出しを抽出できるため、
SEO解析、記事分析、データ収集、コンテンツ整理など、
個人利用から業務用途まで幅広く活用可能です。
2.主な特徴:HTMLから本文を抽出する作業を効率化
複数URLの同時処理で効率化
複数URLをまとめて入力可能。 最大同時処理数を設定することで高速に抽出できます。 キャンセルやリトライ機能も備えているため安定性も抜群です。
見出し・本文の柔軟な抽出設定
h1~h6の見出し、本文を指定可能。
不要な情報を除外して、記事の重要部分だけを効率的に抽出できます。
ノイズ除去で記事内容を精査
ナビゲーション、広告、サイドバー、フッターなどの不要タグを自動除去。
記事本文だけを抽出し、分析・整理が容易になります。
抽出結果の一覧表示と並べ替え
URL、タイトル、本文を一覧表示。 列ヘッダーでソート可能なので、大量のデータもすぐに確認できます。
キーワードフィルター機能
タイトルや本文に含まれるキーワードでフィルターできます。 必要な情報だけを抽出して作業効率を向上できます。
安定したHTTP通信と再試行機能
HTTPリクエストはタイムアウト設定やリトライ機能に対応。 ネットワーク障害時でも安全に抽出を行えます。
3. 使い方
1. ダウンロードとインストール
- ZIP版の場合
- extractarticle100.zip をダウンロード
- ZIPファイルを任意のフォルダに解凍
- 解凍したフォルダ内の
記事本文抽出ツール.exeを起動
2. アプリを起動
- 「記事本文抽出ツール.exe」を起動 (起動時に警告が表示された場合の対処方法)
- アプリの画面が表示される
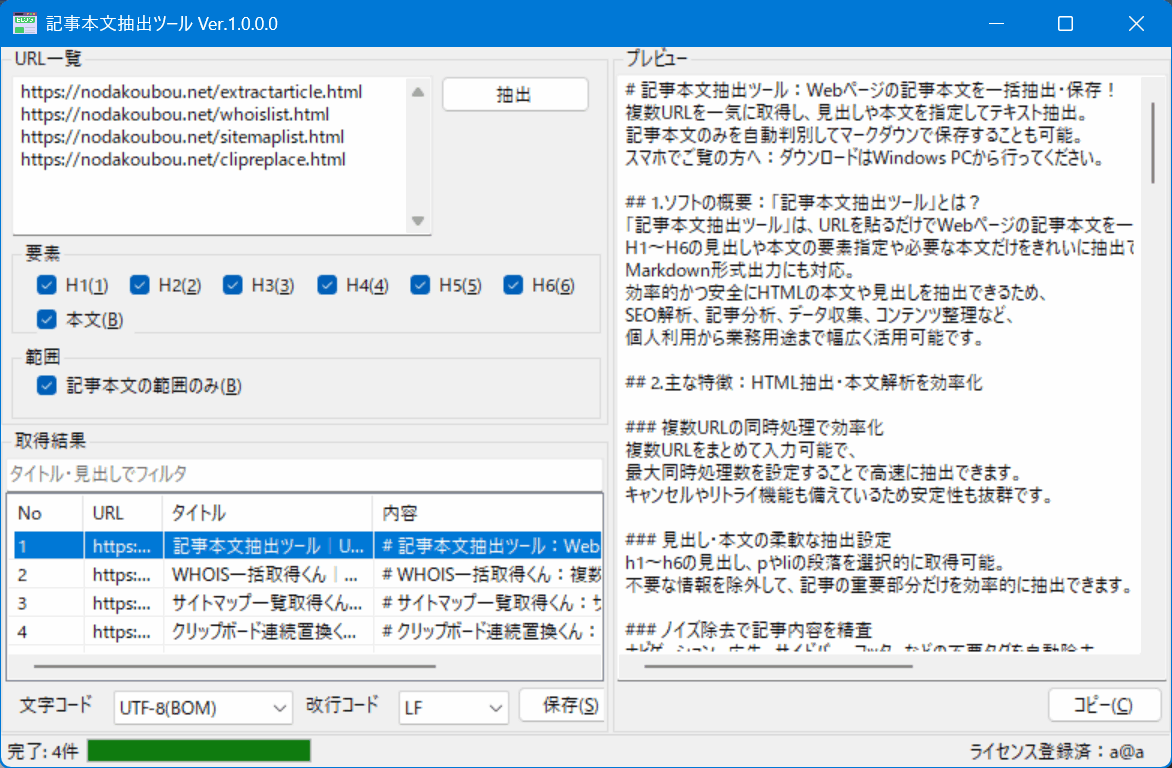
3. 操作方法:記事本文取得からテキストファイル保存まで
- 「記事本文抽出ツール.exe」を起動
- 取得したいWebページのURLを複数行で貼り付けて「抽出」ボタンをクリック
※必要に応じて以下を設定
・抽出したい要素(見出し1~6、本文)
・対象範囲(記事本文の範囲)
例えば、次のように見出しのみの抽出も可能です。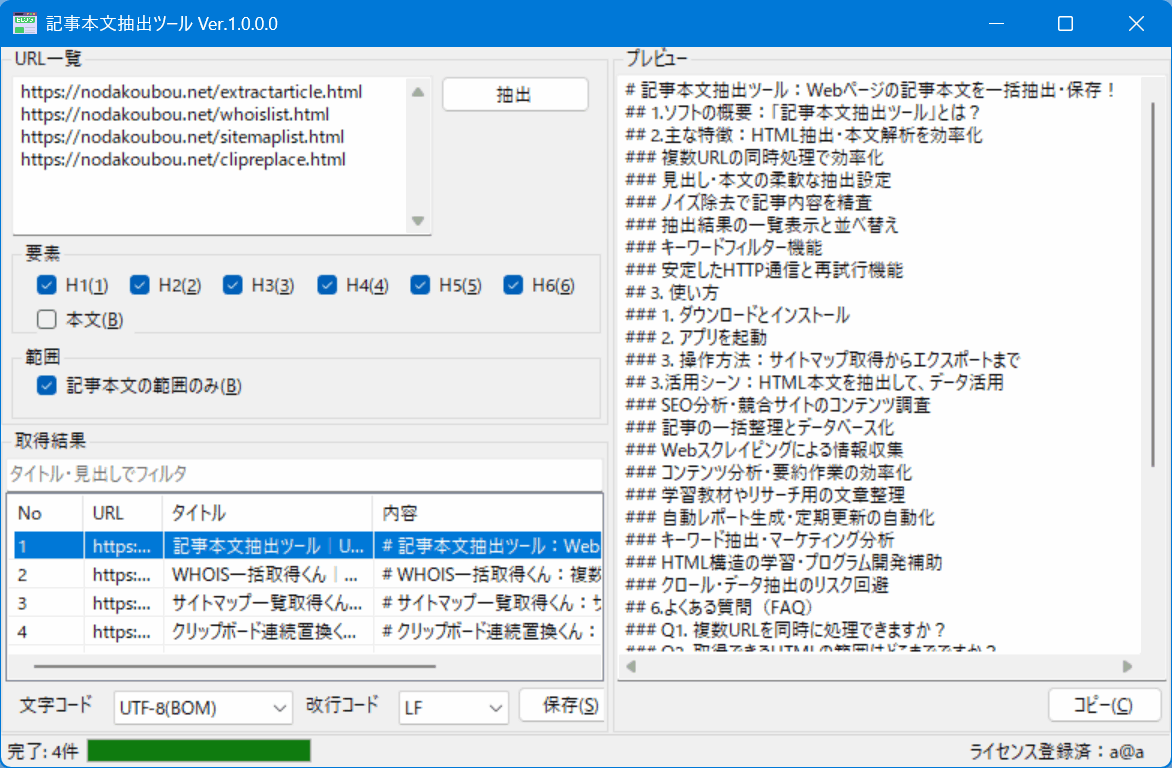
- 見出しと本文が一覧表示。「保存」ボタンでテキストファイルに保存可能
3.活用シーン:HTML本文を抽出して、データ活用
SEO分析・競合サイトのコンテンツ調査
複数の競合ページからh1~h6の見出しや本文を抽出し、
コンテンツ構造やキーワード配置を可視化。
SEO戦略や記事改善の参考に最適です。
記事の一括整理とデータベース化
指定フォルダの複数URLをまとめて抽出し、
「No_タイトル.txt」形式で保存。
大量の記事データをデータベースやCMSに取り込みやすくなります。
Webスクレイピングによる情報収集
記事本文だけを抽出するため、広告やナビゲーションを除外。
ニュース、ブログ、商品説明などの最新情報を効率的に収集可能です。
コンテンツ分析・要約作業の効率化
取得した本文をコピーして要約やレポート作成に活用。
重要箇所のみ抽出できるため、作業時間を大幅に短縮できます。
レポート生成・定期更新の自動化
定期的に複数WebページをMarkdown形式で保存することで、
日報や週報の素材収集を自動化。
業務効率化と情報精度向上に貢献します。
キーワード抽出・マーケティング分析
タイトルや本文に含まれるキーワードでフィルター可能。
市場調査や競合分析、マーケティング戦略策定に活用できます。
6.よくある質問(FAQ)
Q1. 複数URLを同時に処理できますか?
A1. はい、設定で指定した並列数に応じて複数のURLを同時に取得・解析可能です。
高並列にすると処理が早くなりますが、サーバー負荷や回線速度に注意してください。
Q2. 取得できるHTMLの範囲はどこまでですか?
A2. 「記事範囲のみ」を選択すると<article>や<main>内の本文を抽出します。
チェックを外すと<body>全体を取得します。
Q3. 抽出結果に広告やナビゲーションが混ざることはありますか?
A3. 主要なナビゲーション、広告、サイドバーは自動的に除去されます。
ノイズ除去により本文のみを効率的に抽出可能です。
Q4. 本文抽出の対象タグは何ですか?
A4. 見出し(h1~h6)、段落(p)、リスト(li)を抽出可能です。
設定で抽出する見出しレベルや本文のON/OFFを変更できます。
Q5. 処理途中でキャンセルできますか?
A5. はい、抽出実行中に「キャンセル」を押すと処理を中断できます。
中断後は、取得済みデータも保持されます。
Q6. エラーやタイムアウトが発生した場合の対応は?
A6. 設定したリトライ回数と間隔で自動再試行されます。
最大リトライ後にエラーとなった場合、結果に「取得失敗」と表示されます。
Q7. 抽出したデータを保存できますか?
A7. はい、指定フォルダに「No_タイトル.txt」の形式で保存可能です。
Q8. リストビューで抽出結果を並べ替えることはできますか?
A8. はい、列ヘッダーをクリックすることでNo、URL、タイトル、本文の順で昇順・降順に並べ替え可能です。
Q9. フィルター機能はどのように使いますか?
A9. タイトルや本文に含まれるキーワードを入力すると、該当する結果のみを表示できます。
大量データの中から必要な情報を素早く抽出可能です。
6.私が「記事本文抽出ツール」を開発した経緯
開発者自身が、Webページの記事本文のみを抽出・保存し、
PCの読み上げ機能で聞いて情報収集しています。
既存の方法では1ページずつ目視で本文の範囲をコピーする必要があり、
時間がかかるという課題を解決するために「記事本文抽出ツール」を開発しました。
そこで、URLを貼るだけで記事本文のみを一括取得し、
Markdown形式で保存するツールを自作することを決意しました。
- 複数URLの記事本文のみをまとめて高速抽出できる
- H1~H6見出し、本文を指定可能
- Markdown形式で保存し、その後の活用がスムーズ
これにより、従来時間がかかっていた記事収集作業を大幅に効率化できました。
7.更新履歴
Ver.1.0.0:初回リリース
8.修正依頼
機能追加のご要望や不具合報告は、ソフトの機能要望・不具合報告 からご連絡ください。
